
ブラウザにて、指定したエレメントの文字列を抽出するコマンド。抽出した文字列はデータ参照IDに記憶される。
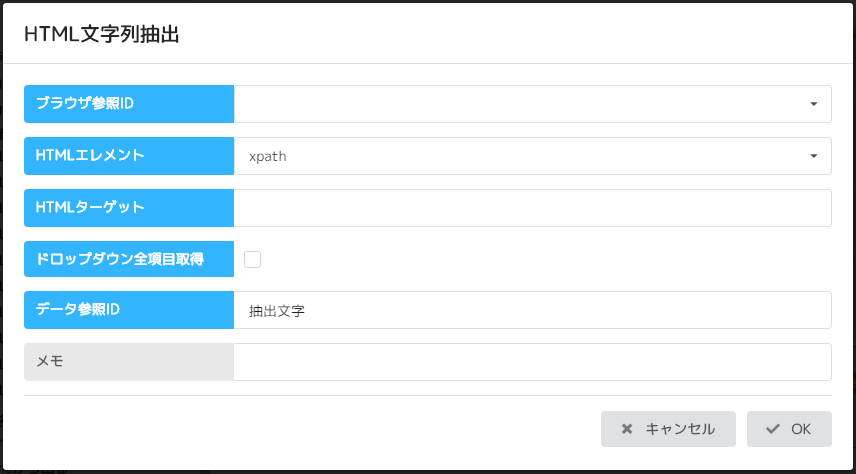
- 名称 内容
- ブラウザ参照ID:定義されたブラウザ参照IDを指定する
- HTMLエレメント:HTMLエレメントを指定する
- HTMLターゲット:指定したエレメントの値を入力する
- ドロップダウン・全項目取得:ドロップダウンの全項目の文字を取得する場合にチェックする
- データ参照ID:取得した文字列を記憶するデータ参照IDを定義する
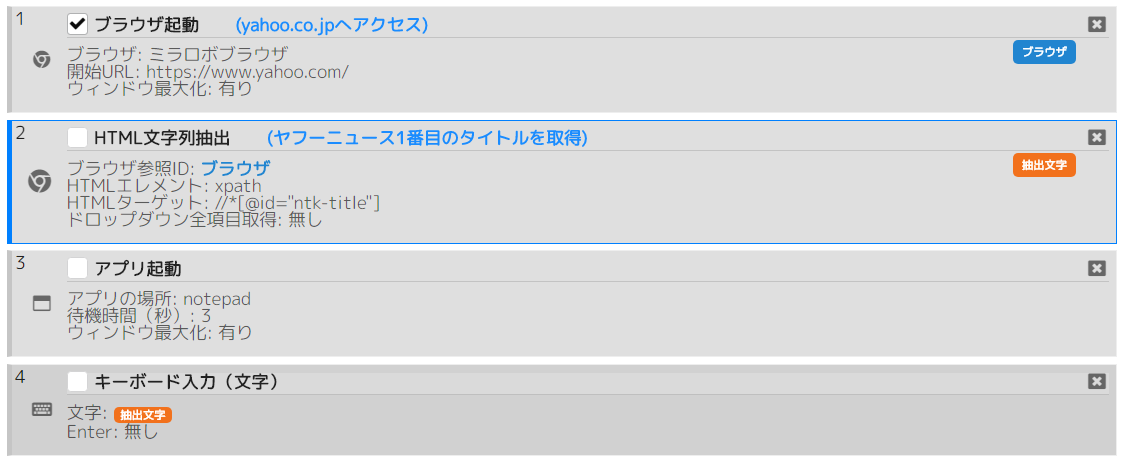
シナリオ例(ページ操作>HTML文字列抽出):
yahooページのニュース1番目の文字列を取得して、メモ帳に入力するシナリオ。
※例のようなHTMLターゲットのxpathを取得する方法は、後述の7. ミラロボブラウザに記載しています。
HTML文字列抽出のHTMLターゲット:
/html/body/div[1]/div/main/div[2]/div[1]/article/div/section/div/div[1]/ul/li[1]/article/a/div/div/h1/span
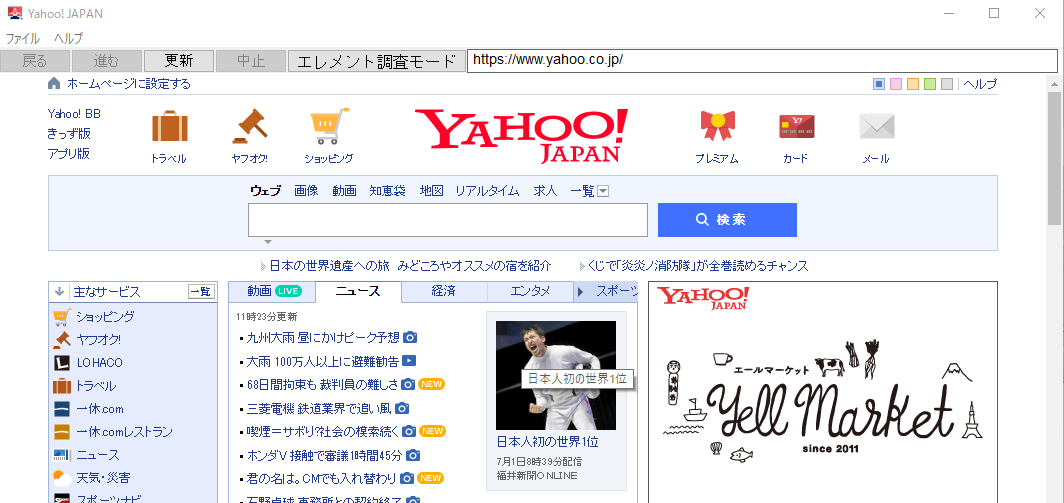
シナリオ例(ページ操作>HTML文字列抽出)の実行結果:
ニュース1番目の文字列がメモ帳に記載された。

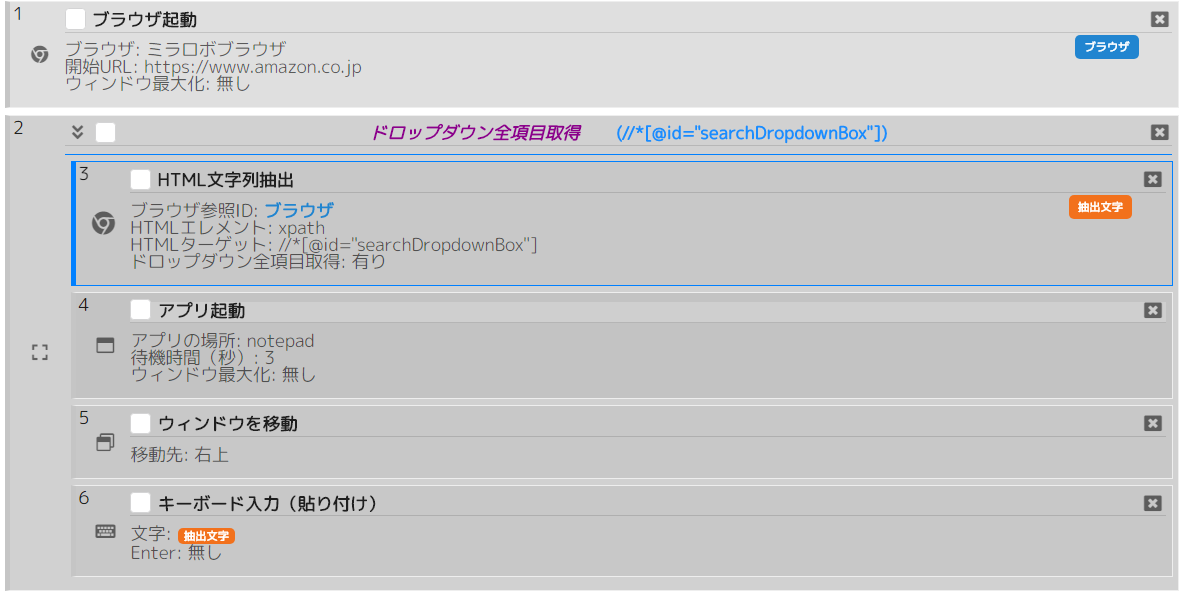
シナリオ例(ページ操作>HTML文字列抽出・ドロップダウン全項目取得):
Amazonページの検索フォームのドロップダウンから全項目を取得し、メモ帳に入力するシナリオ。
※例のようなHTMLターゲットのxpathを取得する方法は、後述の7. ミラロボブラウザに記載しています。
シナリオ例(ページ操作>HTML文字列抽出・ドロップダウン全項目取得)の実行結果:

