
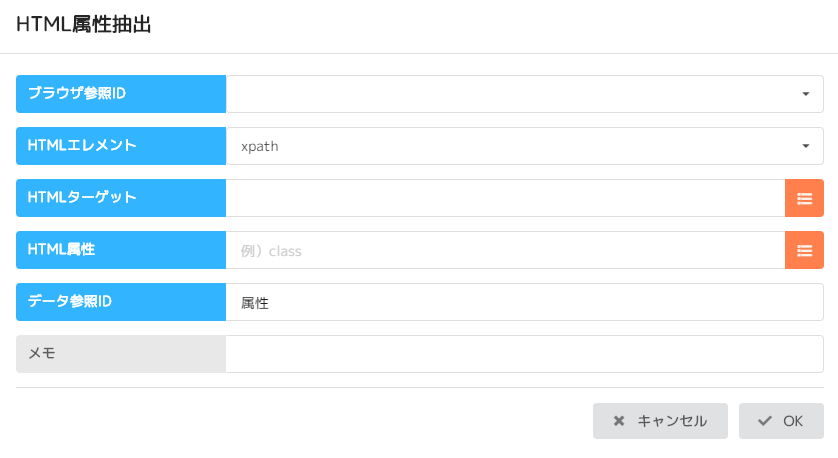
WebページからHTML属性の値を抽出する。
例を以下に示す。本コマンドでは下記表の「属性値」を取得する。
<span class="Fam1ne EBe2gf" aria-label="5 点中 5.0 点の評価、" role="img" style="width:70px">☆☆☆☆☆</span>
- HTML属性 :属性値
- 1 class: Fam1ne EBe2gf
- 2 aria-labe:l 5 点中 5.0 点の評価、
- 3 role: img
- 4 style :width:70px
- 名称: 内容
- ブラウザ参照ID :定義されたブラウザ参照IDを指定する
- HTMLエレメント: HTMLエレメントを指定する ※エレメントのタグがtable, th, tr, tdのいずれかであること
- HTMLターゲット: 指定したエレメントの値を入力する
- HTML属性: 抽出するHTML属性を入力する
- データ参照ID: 取得した文字列を記憶するデータ参照IDを定義する
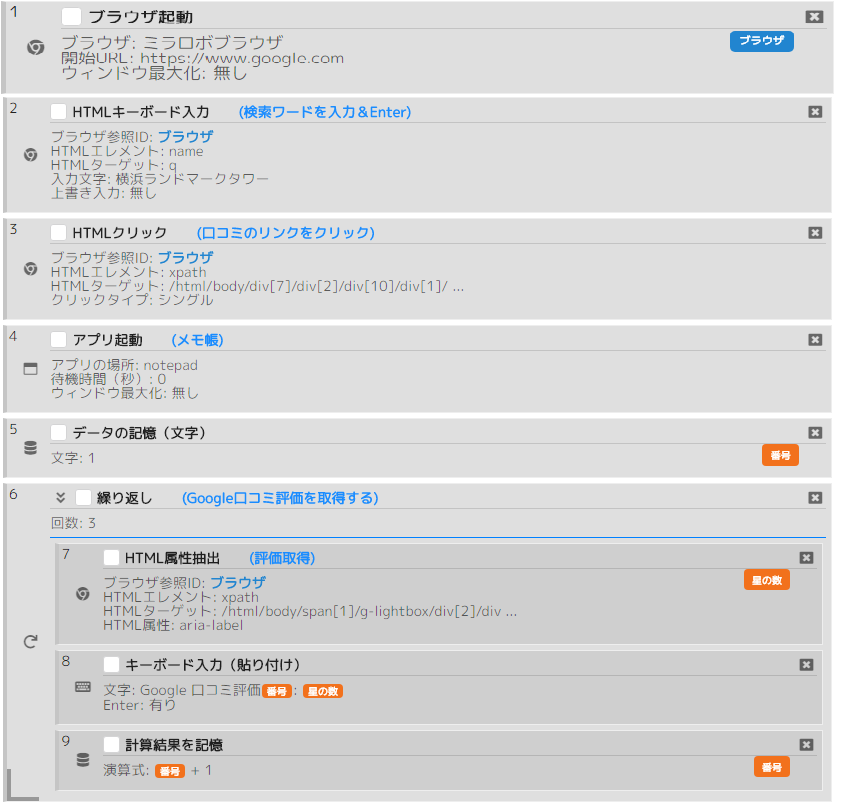
シナリオ例(ページ操作 > HTML属性抽出):
横浜ランドマークタワーのGoogle口コミ評価をメモ帳に入力する。
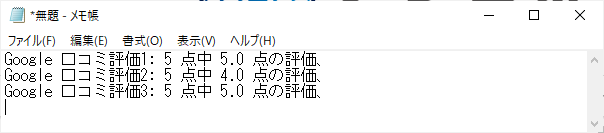
シナリオ例(ページ操作 > HTML属性抽出)の実行結果:
例のようなTHMLターゲットのxpathを取得する方法は、後述の7.ミラロボブラウザに記載しています。