ルール(正規表現)に一致する文字列を抽出するコマンド。ルールに括弧がある場合、その中身だけを抽出する。
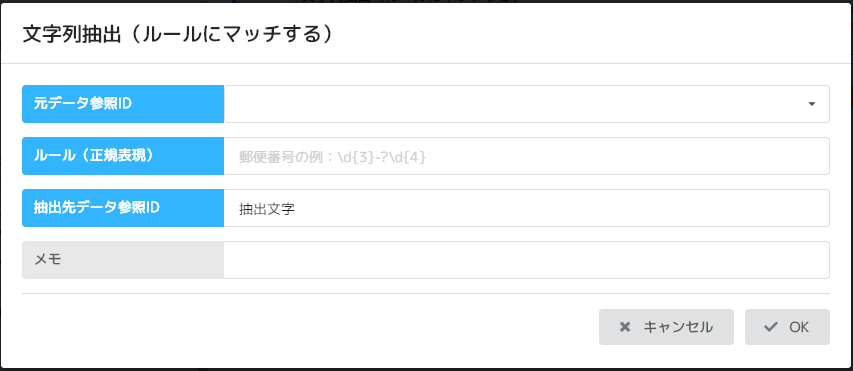
- 名称 内容
- 元データ参照ID:ファイルパスが定義されているデータ参照IDを指定する
- ルール(正規表現):ルールを定義する
- 抽出先データ参照ID:抽出したファイル名またはフォルダ名を記録するための データ参照IDを定義する
正規表現とは、簡単に説明すると、「ある定義に沿った形式で文字列を表現する方法」である。その定義を一部抜粋したものを以下に示す。
- 記号 記号の読みと意味
- .:ドット、任意の一文字
- *:アスタリスク、直前の文字の0回以上の繰り返し
- +:プラス、直前の文字の1回以上の繰り返し
- [ ]:[]内のどれか1文字 例:[a-z] だと、a, b, c, …, z からどれか1文字があればマッチする
- {n}:直前の文字をn回繰り返す
- {min, max}:直前の文字をmin以上max以下繰り返し
- (A|B ):パターンAまたはパターンBのどちらか 例:(.*道 | .*県) だと、~道または~県にマッチする
- ¥w:アルファベット、数字、アンダースコアのどれか1文字
- ¥W:アルファベット、数字、アンダースコア以外のどれか1文字
- ¥d:数字1文字
- ¥s:半角スペース、タブ、改行のどれか1文字
- ¥:エンまたはバックスラッシュ 特殊文字をマッチさせるために、特殊文字の直前に入力する記号。 特殊文字:.(ドット), *, +, -, ¥など 使い方:「abc¥def」で「¥d」にマッチするルールは『¥¥d』
※この他にも様々な定義があるので「正規表現 一覧」や「正規表現 郵便番号」などで検索してください。
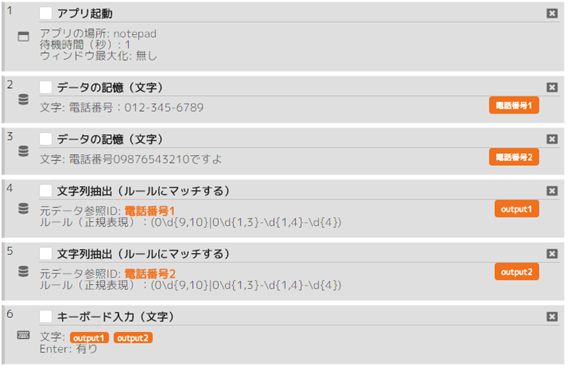
シナリオ例(ルールにマッチ・電話番号):
ハイフンある場合とない場合の電話番号両方を抽出するシナリオ。
- ハイフン有り電話番号・ハイフン無し電話番号:(0¥d{9,10}|0¥d{1,3}-¥d{1,4}-¥d{4})
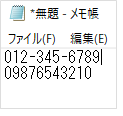
シナリオ例(ルールにマッチ・電話番号)の実行結果:
シナリオ例(ルールにマッチ・電話番号verシンプルルール):
電話番号(数字-数字-数字)を抽出しメモ帳に入力する。
- 電話番号:(¥d+-¥d+-¥d+)
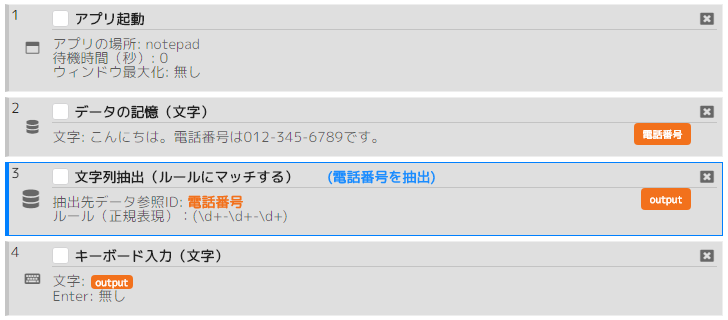
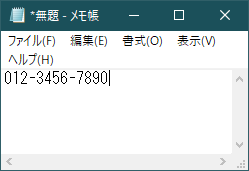
シナリオ例(ルールにマッチ・電話番号verシンプルルール)の実行結果:
シナリオ例(ルールにマッチ・メールアドレス):
メールアドレスを抽出してメモ帳に入力するシナリオ。
- メールアドレス:Email: ([¥w¥.¥-]+@[¥w¥.¥-]+)
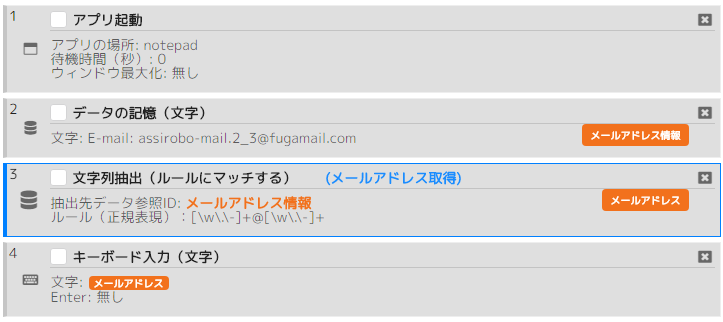
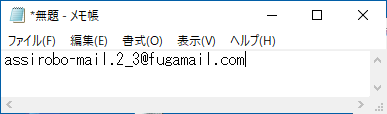
シナリオ例(ルールにマッチ・メールアドレス)の実行結果:
シナリオ例(ルールにマッチ・都道府県):
住所から都道府県を抽出してメモ帳に入力するシナリオ。
- 都道府県:.*[都道府県]
- 都道府県:[ぁ-ん亜-熙]+[都道府県]
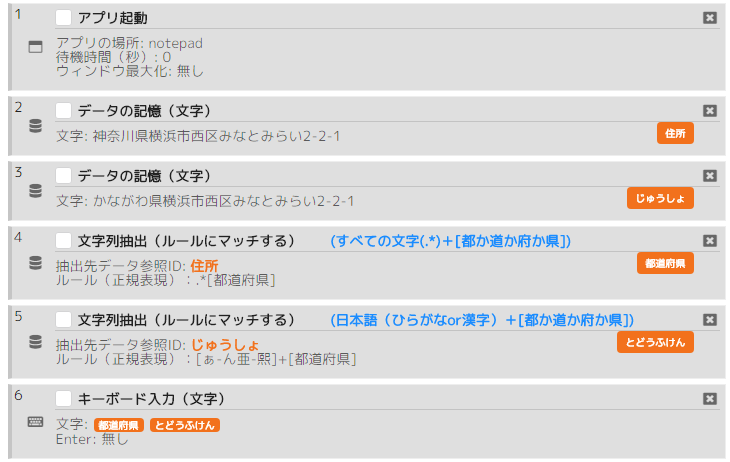
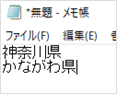
シナリオ例(ルールにマッチ・都道府県)の実行結果:
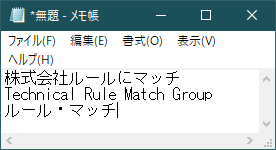
シナリオ例(ルールにマッチ・テンプレート):
下図のようにフォーマットが決まっている文字列から会社名、部署、氏名を抽出し、メモ帳に入力する。
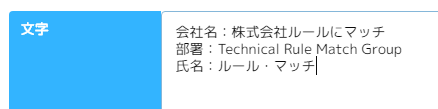
- ()内のすべての文字列: 会社名:(.*)
- ()内のすべての文字列: 部署:(.*)
- ()内のすべての文字列: 氏名:(.*)
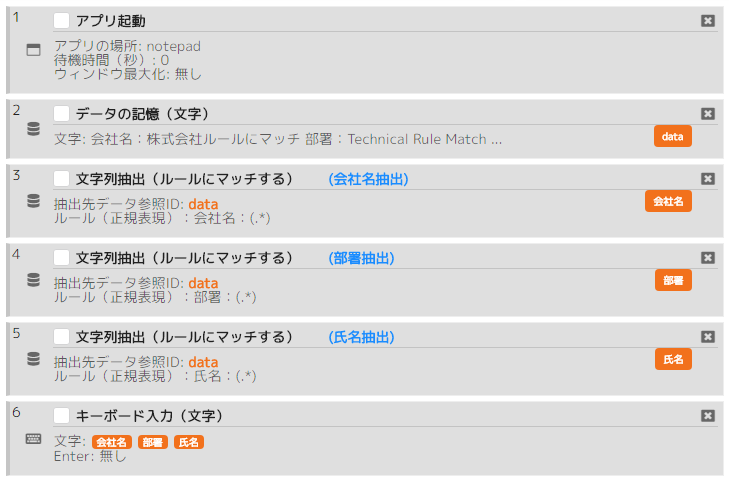
シナリオ例(ルールにマッチ・テンプレート)の実行結果: